Embedding
Esta funcionalidad permite gestionar y optimizar el almacenamiento de vectores utilizados en el análisis de similitud y búsqueda de información en modelos de embedding. Su propósito es estructurar la información en una base de conocimiento eficiente, facilitando la evaluación de consultas mediante la recuperación de datos relevantes a partir de representaciones vectoriales.
Esta tabla está directamente relacionada con la acción Embedding OpenAI V3
El acceso a la configuración de Embeding está disponible en el menú lateral izquierdo de la interfaz principal de Lynn.
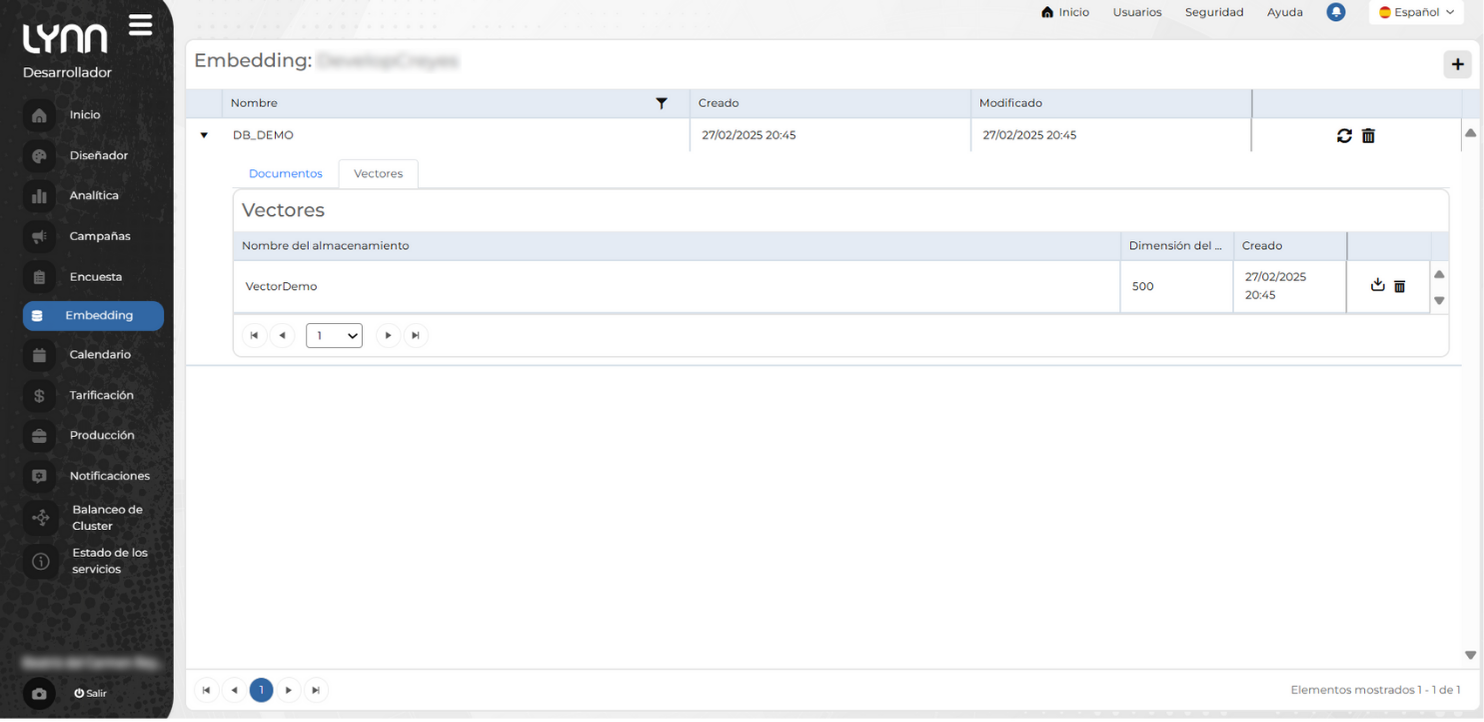
En la vista principal de la opción Embeding, la información se presenta en una tabla que muestra los siguientes datos:
Nombre: Nombre del embedding.
Creado: Fecha y hora de creación.
Modificado: Fecha y hora de la última modificación.
Guía para Crear un Embeding
Una vez en la vista principal del módulo de Embedding:
Hacer clic en el botón Agregar, ubicado en la esquina superior derecha de la vista.
Esto actualizará la vista para mostrar un conjunto de campos necesarios para la creación y personalización del Embedding.
Completa los campos requeridos:
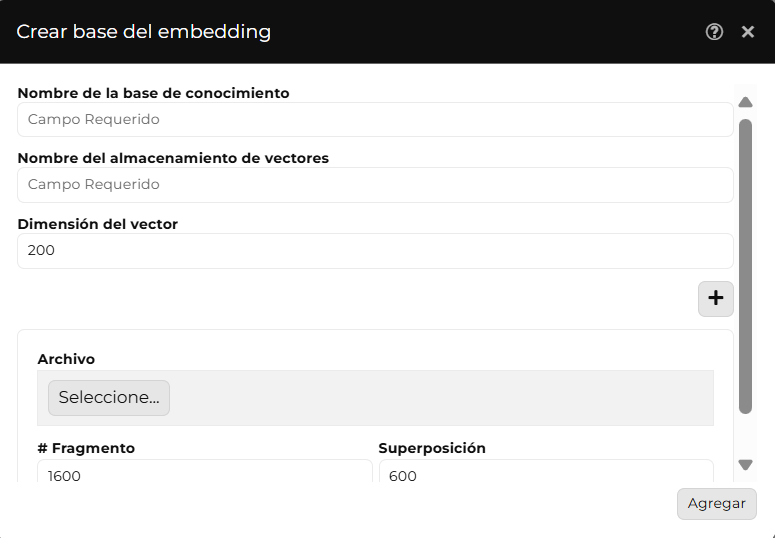
Nombre de la base de conocimiento: Campo de entrada de tipo String para el identificador único y descriptivo del Embedding.
Nombre del almacenamiento de vectores: Campo de entrada de tipo String para defnir el nombre del espacio donde se almacenan los vectores generados a partir del modelo de embedding, permitiendo su posterior comparación y análisis..
Dimensión del vector: Campo de entrada de tipo tipo Number para definir el número de valores numéricos que conforman cada vector en la representación de los datos. Afecta la precisión y el rendimiento del modelo en la búsqueda de similitud.
Archivo: Campo de entrada de tipo File para cargar el documento que contiene la información base que será procesada para generar los vectores de embedding.
Note
Actualmente, solo se admiten archivos con extensión .md (Markdown).
Fragmento: Campo de entrada de tipo Number para definir el tamaño de cada sección de texto extraída del archivo original para convertirla en un vector.
Superposición: Campo de entrada de tipo Number para definir la cantidad de texto compartido entre fragmentos consecutivos, lo que permite mantener coherencia en el análisis y mejorar la recuperación de información en búsquedas vectoriales.
Note
El formulario incluye un botón Agregar (+) que permite cargar múltiples archivos con la información base o base de conocimientos. Cada archivo puede configurarse con los campos Fragmento y Superposición.
Hacer clic en el botón agregar luego de completar todos los campos de configuración.
Tabla de Embedding
Los datos de creación de un embedding se presentan en una tabla organizada en diferentes secciones para facilitar su consulta y gestión. Al expandir un embedding, se muestran dos pestañas:
- Nombre: Nombre del embedding.
- Creado: Fecha y hora de creación.
- Modificado: Fecha y hora de la última modificación.
- Documentos: Contiene la lista de archivos utilizados para generar el embedding, junto con los parámetros de segmentación.
- Vectores: Muestra la configuración del almacenamiento de vectores generados a partir de los documentos procesados.
- Reprocesar: Procesar documentos cargados.
Reprocesar
Esta funcionalidad permite procesar nuevamente documentos almacenados en la base de conocimientos, ya sean documentos previamente procesados o archivos recientemente cargados mediante la opción Adjuntar Documento en la pestaña Documentos de la tabla de embedding.
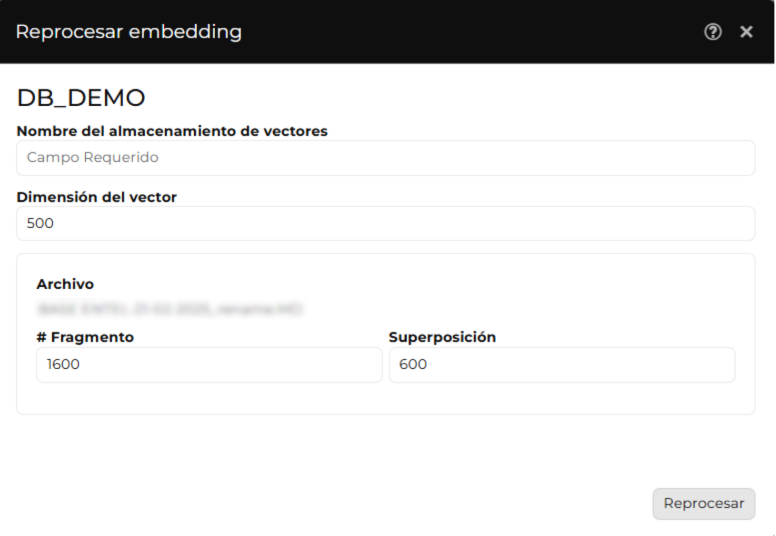
Pasos para reprocesar un documento:
- Hacer clic en la opción Reprocesar.
- Verificar que los documentos que se desean usar como base de conocimientos estén en la lista. Si algún documento no aparece, primero debe Adjuntar Documento.
- Si el documento no ha sido procesado previamente, ingresar los valores de:
- Número de fragmentos: Tamaño en caracteres de cada bloque de texto.
- Solapamiento: Cantidad de texto compartido entre fragmentos consecutivos.
- Hacer clic en el botón Reprocesar para iniciar el procesamiento con los parámetros definidos.
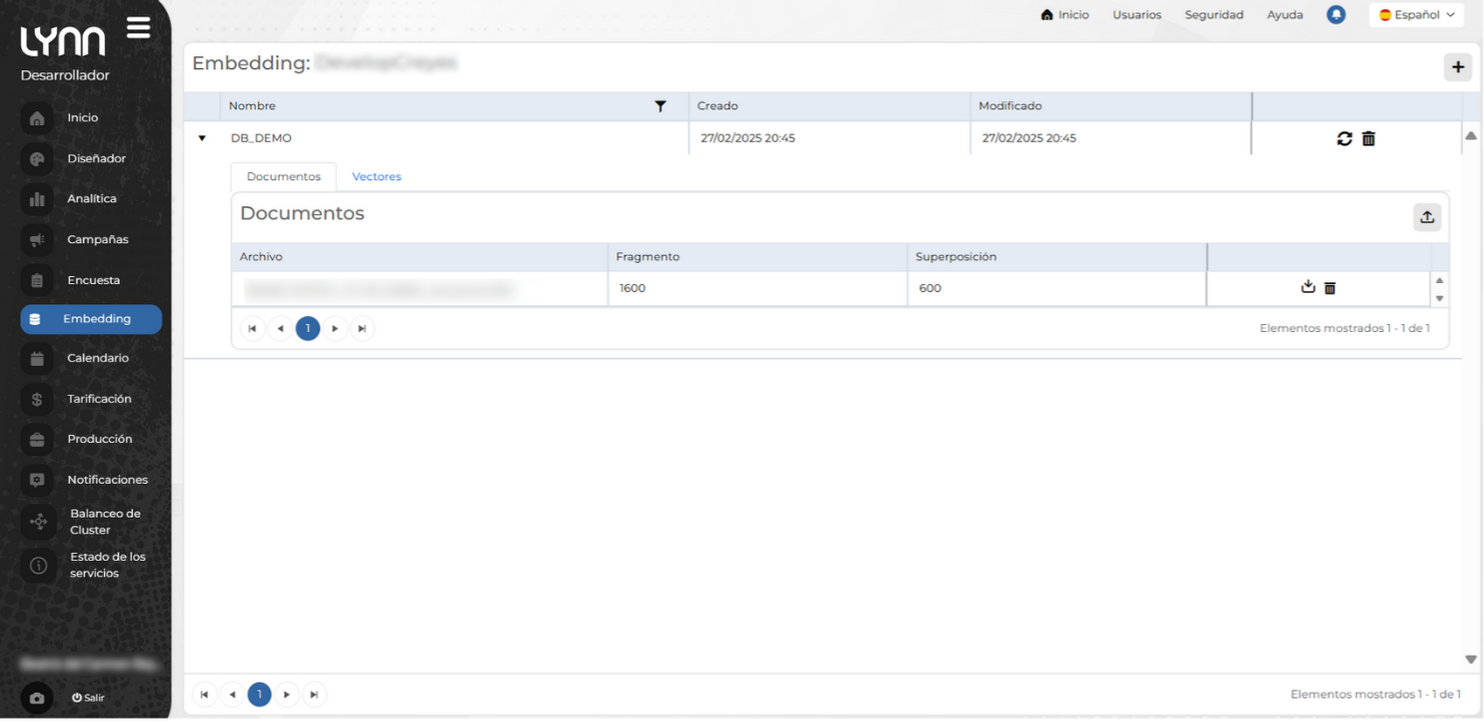
Pestaña: Documentos
Esta sección muestra los archivos utilizados para la creación del embedding, junto con sus parámetros de segmentación, de los que se muestran datos como:
- Archivo: Nombre del documento procesado.
- Fragmento: Tamaño en caracteres de cada bloque de texto convertido en un vector.
- Superposición: Cantidad de texto compartido entre fragmentos consecutivos para mejorar la continuidad semántica.
- Descargar documentos
- Eliminar documentos
Adjuntar documento
Permite cargar un archivo en la base de conocimientos sin procesarlo inmediatamente. El documento se almacena en el sistema, pero no se generan representaciones vectoriales ni se aplica segmentación en esta etapa. El procesamiento y la generación de vectores se pueden realizar posteriormente.
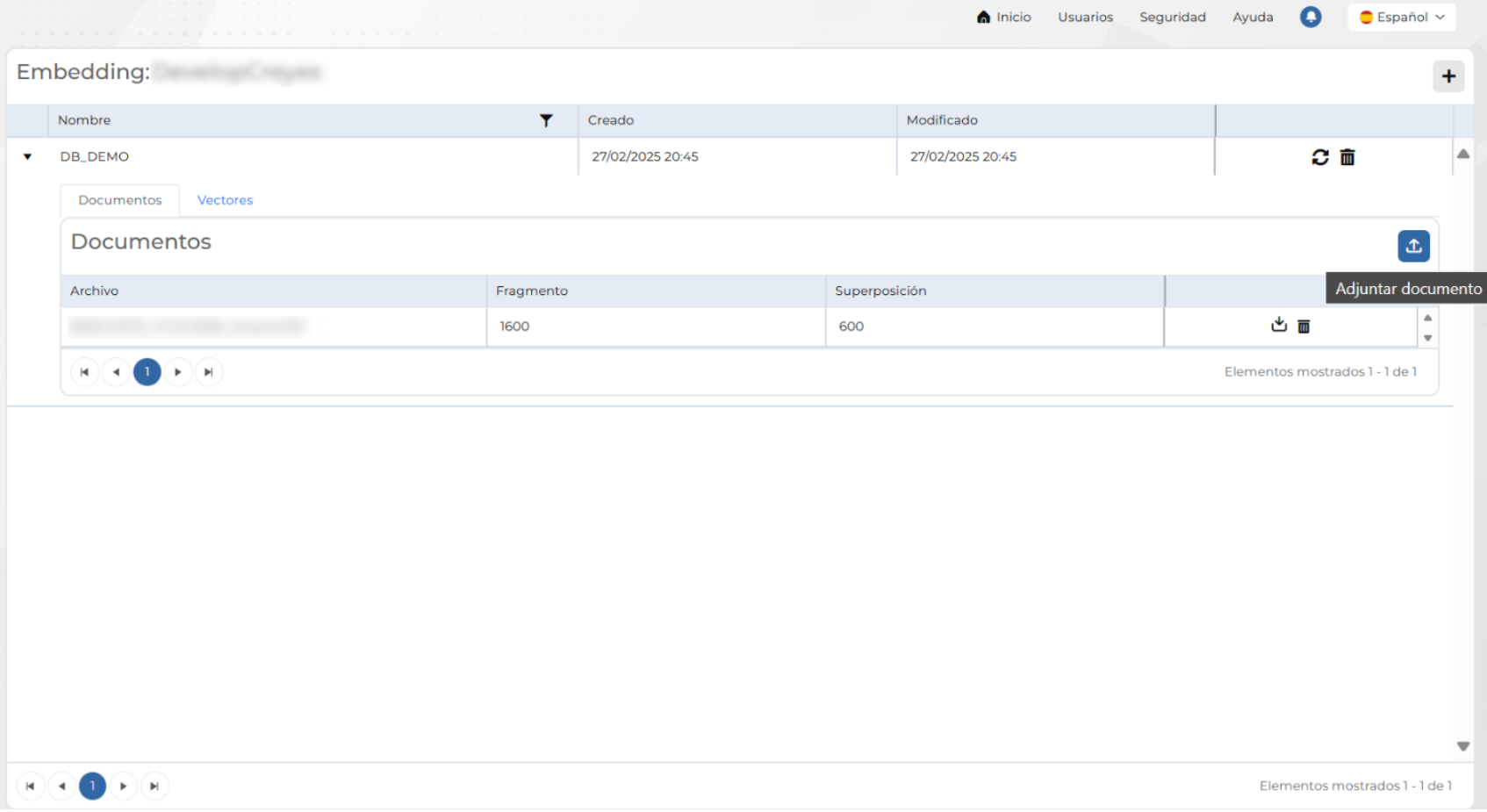
Important
Al adjuntar un documento, no se definen fragmentos ni solapamiento, ya que el procesamiento aún no ocurre. El documento queda disponible para ser procesado en una etapa posterior mediante la opción Reprocesar.
Pestaña: Vectores
Muestra la configuración del almacenamiento de los vectores generados a partir de los documentos procesados.
- Nombre del almacenamiento: Identificador del espacio donde se almacenan los vectores generados.
- Dimensión del vector: Número de valores numéricos que componen cada vector, lo que impacta en la precisión de la búsqueda vectorial.
- Creado: Fecha y hora de creación del almacenamiento de vectores.
- Descargar vectores
- Eliminar vectores