



Genesys Cloud Audio Connector
Este canal permite la comunicación entre Lynn y el servicio de voz de Genesys Cloud, utilizando mecanismos de conversión de voz a texto (Speech-to-Text) y de texto a voz (Text-to-Speech) para habilitar una experiencia conversacional completa. Mientras Genesys gestiona el audio, Lynn interpreta y responde mediante texto procesado. Por lo tanto, el diseño del IVR puede realizarse directamente desde Lynn.
Pre-requisitos
- Credenciales y configuración para Text-to-Speech - ElevenLabs.
Cuenta activa en ElevenLabs.
Clave API (API Key) válida. Cómo obtenerla:
- Iniciar sesión en ElevenLabs
- Ir a la esquina inferior izquierda y hacer clic en My Account.
- Seleccionar la opción API Keys.
- Hacer clic en Create API Key para generar una nueva clave.
Important
La clave completa solo se mostrará una vez, en el momento de su creación. Asegúrate de copiarla y guardarla en un lugar seguro. Posteriormente, solo estarán visibles los últimos cuatro caracteres.
Voz configurada en la cuenta (obtener el Voice ID desde el panel de ElevenLabs).
Formato de salida compatible (mp3, wav).
(Opcional) Configuración de idioma, estilo o parámetros de voz según el flujo.
- Credenciales y configuración para Speech-to-Text (Azure Speech Services)
- Cuenta activa en Microsoft Azure.
- Servicio de Speech creado en el portal Azure.
- Claves necesarias:
- Speech API Key
- Cómo obtenerla:
- Ir al portal Azure
- CCrear o acceder al recurso Speech Service.
- Ir a la sección Keys and Endpoint.
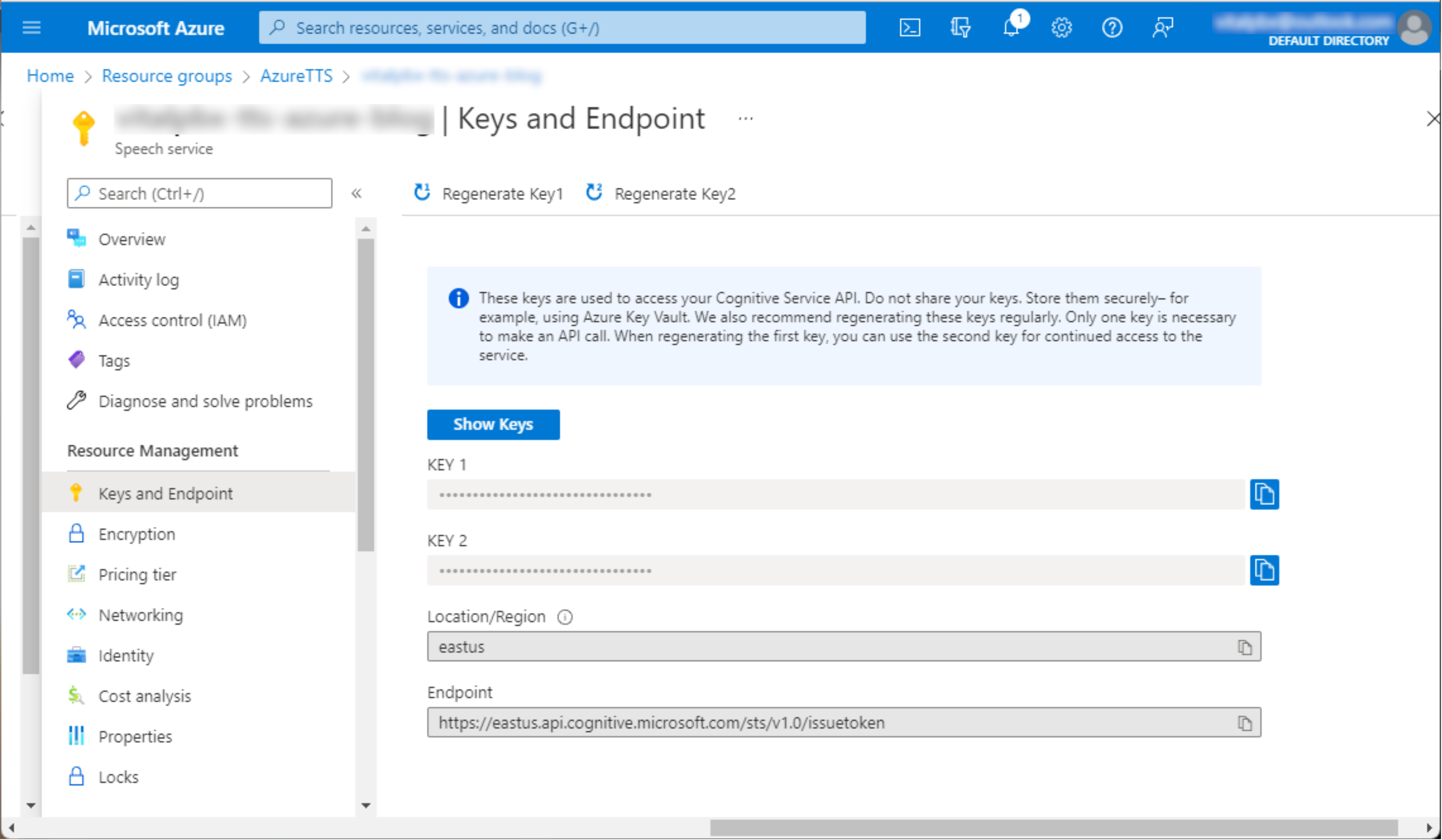
- Cómo obtenerla:
- Región correspondiente al recurso (por ejemplo: eastus).
- Speech API Key
- Idioma configurado para el reconocimiento de voz (por ejemplo: es-ES, en-US).
- Permisos habilitados para consumir el endpoint de Speech-to-Text.
- AVerificar que el formato de audio enviado sea compatible (por ejemplo: PCM 16 kHz, mono).
Pasos para la creacion del canal
- Inicia sesión en Lynn.
- Seleccionar la opción Diseñador desde el menú principal de Lynn ubicado en el lateral izquierdo de la vista.
- Hacer clic derecho sobre el área libre del diseñador.
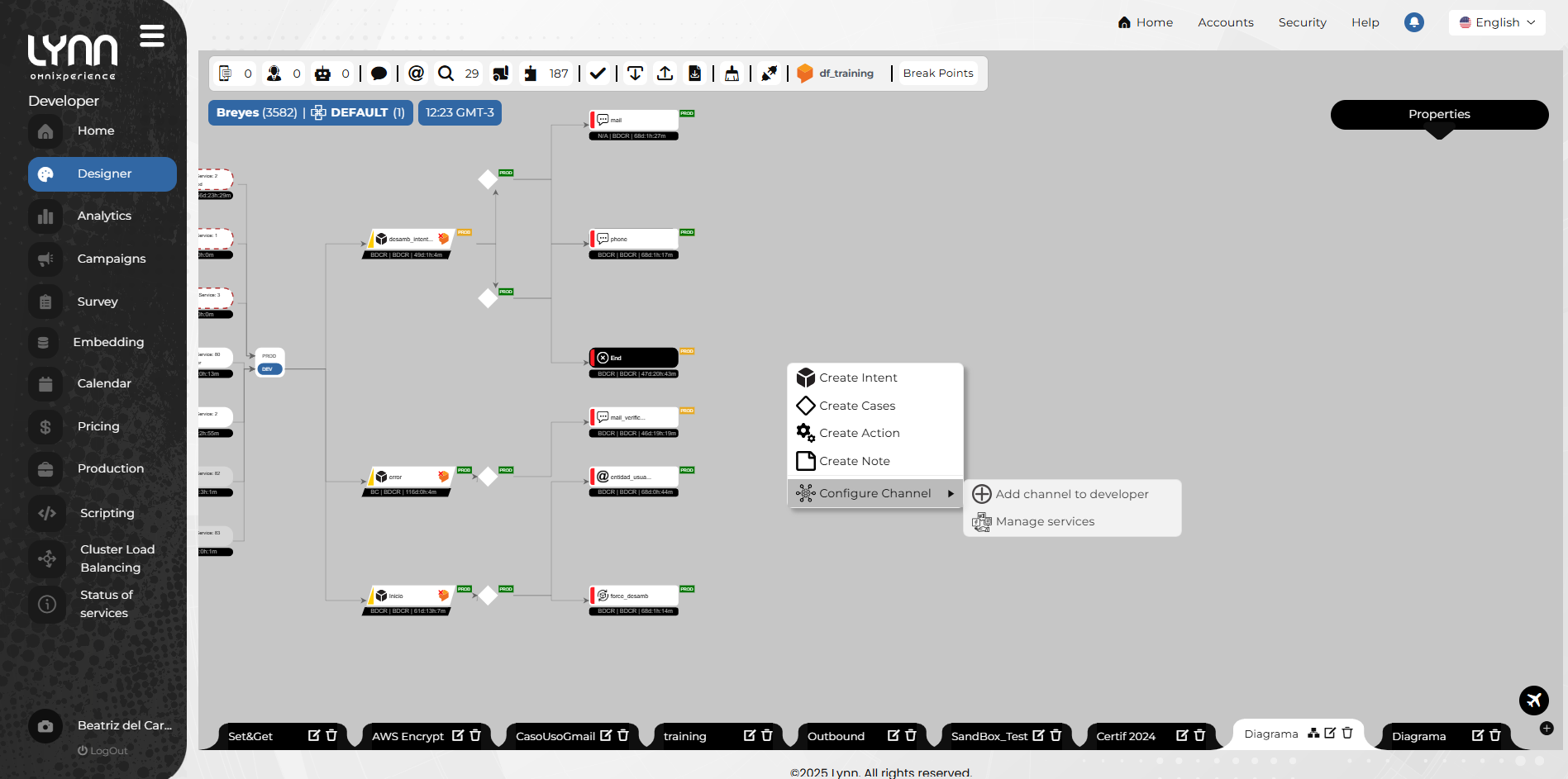
Se mostrará un menú contextual.
- Seleccionar Configurar canal y luego Agregar canal a [Ambiente].
- Elegir Genesys Cloud Audio Connector de la lista de canales disponibles en Lynn.
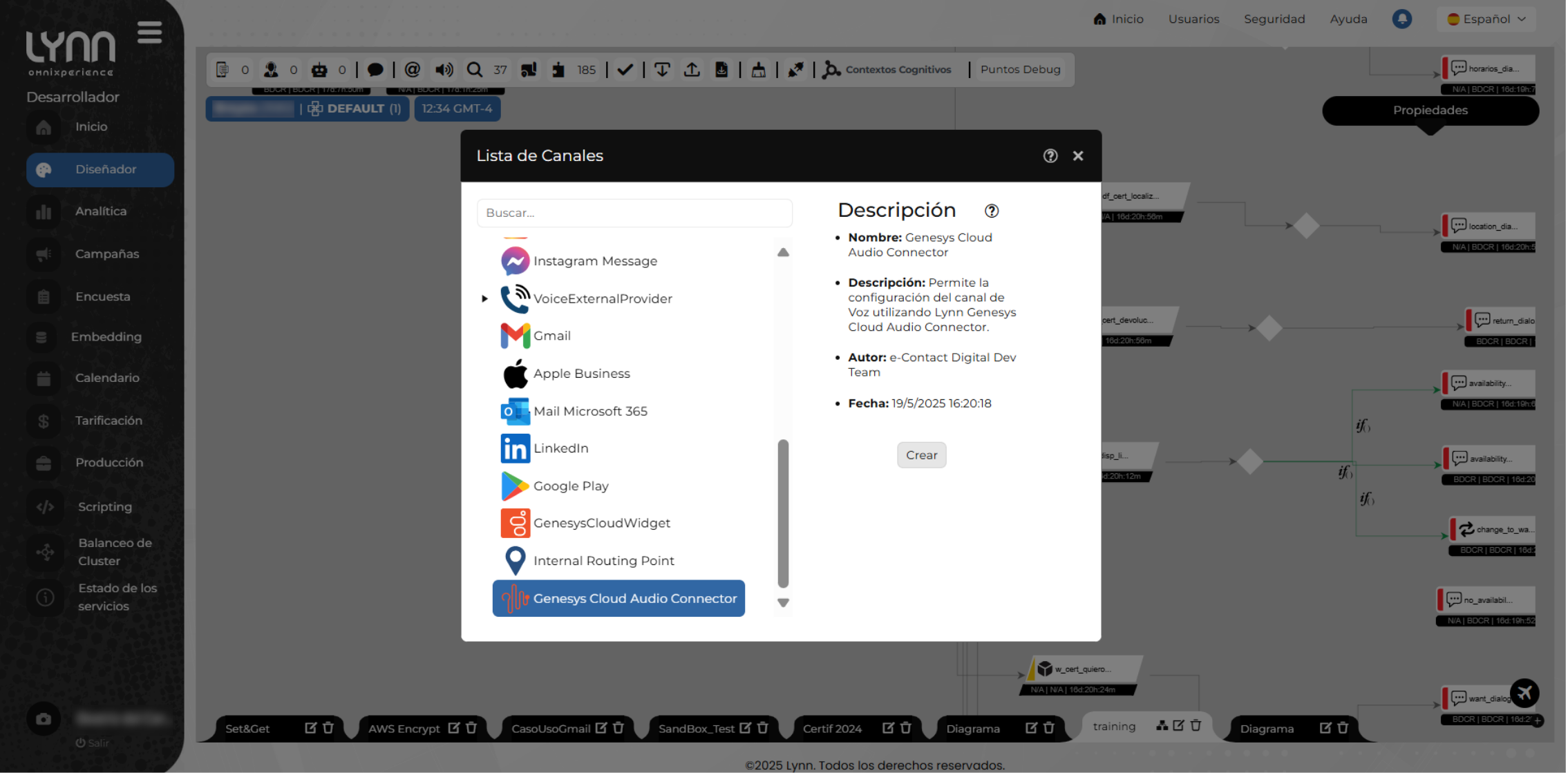
- Hacer clic en Crear.
Se mostrará una ventana con los campos requeridos para configurar el canal.
- Hacer clic en el botón Verificar para inicializar el proceso de validación de parámetros. Luego, pulsa Crear.
El sistema mostrará un mensaje emergente confirmando la creación exitosa del canal.
- Activar el canal: haz clic derecho sobre la burbuja del canal creado. Se mostrará un menú contextual. Selecciona Activar. El canal cambiará a un estado blanco sólido, indicando que está activo.
Campos de configuración del canal
Para que el canal funcione correctamente, es necesario establecer ciertas configuraciones, entre ellas los motores que se utilizarán para procesar el audio: uno encargado de convertir la voz en texto (Speech-to-Text) y otro responsable de sintetizar audio a partir de texto (Text-to-Speech).
Configuración del proveedor Text-to-Speech
Seleccione un proveedor (TTS_PROVIDER): Campo de tipo select para elegir el proveedor del servicio que convierte texto en audio mediante voces sintéticas.
Note
Actualmente, el único proveedor de TTS disponible para este canal es ElevenLabs.
Ingrese las credenciales (TTS_CREDENTIALS): Campo de tipo text para ingresar la API Key de ElevenLabs. Consulta los pre-requisitos para más detalles sobre la configuración del canal.
Important
Este campo cuenta con un botón de validación que permite verificar inmediatamente si las credenciales ingresadas son correctas antes de guardar la configuración. Al ingresar las credenciales y hacer clic en Validar, el sistema intentará conectarse con el servicio:
- Si la autenticación es exitosa, se mostrará un ícono de check en color verde
- Si las credenciales son incorrectas o ocurre un error de conexión, se mostrará un ícono de advertencia en color rojo, lo que permite corregir los datos antes de continuar.
Seleccione una de las voces disponibles en su cuenta (TTS_VOICE): Campo de tipo select para elegir una de las voces habilitadas en ElevenLabs.
Configuración de la voz. (TTS_VOICE_SETTINGS): Sección que agrupa los campos necesarios para personalizar la salida de voz generada por el motor TTS, ajustando la entonación, naturalidad, estilo y velocidad del habla. Todos los campos numéricos deben completarse con valores entre 0 y 1.
Stability: Campo de tipo number que controla la consistencia emocional de la voz.
- Valores bajos: mayor variabilidad emocional.
- Valores altos: voz más estable y monótona.
Note
Valor por defecto:
0.5.Similarity Boost: Campo de tipo number para aumentar la fidelidad respecto a la voz original.
- Valores altos aumentan la semejanza, pero pueden generar artefactos si la muestra de origen tiene ruido.
Note
Valor por defecto:
0.75.Style: Campo de tipo number para amplificar el estilo del hablante.
- Valores altos pueden exagerar la expresividad, afectando la estabilidad y aumentando la latencia.
Note
Valor por defecto:
0.0.Use Speaker Boost: Campo de tipo select para activar o desactivar el refuerzo de la identidad vocal del hablante.
- Utiliza el valor
truesi se desea reforzar la identidad del hablante, especialmente útil cuando se emplean múltiples voces.
Note
Valor por defecto:
false. Activarlo puede incrementar la latencia y el uso de recursos.- Utiliza el valor
Speed: Campo de tipo select para definir la velocidad de reproducción de la voz.
- Valores menores a 1.0 ralentizan la voz, mientras que valores mayores a 1.0 la aceleran.
- Por ejemplo: 1.0 corresponde a velocidad normal, 1.2 es un 20% más rápido.
Note
Valor por defecto:
1.0. Tieme un mínimo recomendado de0.7(30% más lento que la velocidad normal) y un máximo permitido de1.2(20% más rápido que la velocidad normal)Model: Campo de tipo select para especificar el modelo de síntesis de voz a utilizar.
Configuración del proveedor Speech-to-Text
Seleccione un proveedor (STT_PROVIDER): Campo de tipo select para elegir el motor de Speech-to-Text (STT) a utilizar..
Important
Actualmente, el único proveedor de Speech-to-Text disponible para este canal es Azure.
Ingrese las credenciales. (STT_CREDENTIALS):
Sección que agrupa los campos necesarios para autenticar la conexión con Azure Speech Services. Estos datos deben obtenerse desde el portal de Azure.
Endpoint: Campo de tipo text para ingresar para ingresar la URL base del servicio de Azure Speech. Este valor identifica el punto de conexión con el servicio. Ver Endpoints por región
SubscriptionKey: Campo de tipo text donde se debe ingresar la clave de suscripción del recurso de Azure Speech. Esta clave autentica las solicitudes enviadas al servicio y está asociada a una cuenta de Azure con permisos habilitados para Speech-to-Text. Consulta los Pre-requisitos para más detalles..
Region: Campo de tipo text que se debe completar con la región geográfica donde está desplegado el servicio (por ejemplo,
eastus).Note
El valor de la región forma parte del Endpoint y puede usarse para autocompletar este campo.
Language: Campo de tipo select para seleccionar el código de idioma correspondiente al audio que se desea reconocer. Por ejemplo:
es-ES(español - España),en-US(inglés - EE.UU.). Este parámetro mejora la precisión del reconocimiento de voz.
Parámetros funcionales
Tiempo de inactividad para finalizar la interacción, por parte de Lynn (milisegundos): Campo de tipo number para definir el tiempo máximo de inactividad del usuario (sin entrada de voz) antes de que Lynn cierre automáticamente la interacción. Se expresa en milisegundos.
Tiempo de espera antes de comenzar el reconocimiento de voz (segundos): Campo de tipo select para establecer un retardo inicial, en segundos, antes de activar el reconocimiento de voz. Es útil para evitar captar sonidos irrelevantes o solapamientos con mensajes del sistema.
De forma random se ejecuta uno de estos diálogos mientras se crea la sessión del asistente virtual: Campo de tipo textarea para ingresar una lista de frases que pueden ejecutarse aleatoriamente mientras se inicializa el asistente virtual, con el fin de mantener informado o entretenido al usuario.
Intención a ejecutar cuando ocurre un silencio: Campo de tipo select para elegir la intención que se ejecutará automáticamente si se detecta un periodo prolongado de silencio por parte del usuario, permitiendo retomar o redirigir la conversación.
Intención a ejecutar cuando el cliente interrumpe el mensaje: Campo de tipo select para definir la intención que se activará si el usuario comienza a hablar mientras Lynn está reproduciendo un mensaje, permitiendo gestionar interrupciones de forma contextual.
Intención a ejecutar cuando ocurre un error: Campo de tipo select para seleccionar la intención que se ejecutará si ocurre un error durante el procesamiento de voz, como fallos del motor STT o problemas de conexión.
Tamaño del buffer que se espera para enviar al proveedor de Speech-to-Text (en segundos): Campo de tipo select para elegir la duración del fragmento de audio (en segundos) que se agrupa y envía al proveedor STT. Este valor influye en el tiempo de respuesta y la precisión del reconocimiento.
Permitir interrupciones por voz: Campo de tipo radio button para habilitar o deshabilitar la posibilidad de que el usuario interrumpa mensajes hablados de Lynn mediante entrada de voz. Si está activado, el sistema detendrá el mensaje y procesará la voz del usuario.
Umbral de silencio. (en segundos): Campo de tipo select para definir el tiempo de silencio consecutivo que se interpretará como el final de una frase. A menor valor, el sistema será más sensible a pausas breves.