



Health
Este reporte presenta una topología similar al Application Map, una característica de monitoreo en Azure que forma parte de Application Insights, un servicio de gestión del rendimiento de aplicaciones (APM) diseñado para desarrolladores web.
Application Insights es un servicio de Microsoft Azure que ofrece herramientas para monitorizar, analizar y detectar errores de rendimiento en aplicaciones alojadas en la nube. También permite insertar trazas personalizadas y registrar errores.
El mapa de la aplicación permite visualizar la estructura completa de la aplicación a través de componentes interconectados. Estos componentes están identificados por las llamadas de dependencia HTTP realizadas entre servidores que tienen el SDK de Application Insights instalado.
Botones principales (ubicados en la parte superior izquierda):
- Back: Retrocede al nivel anterior tras ingresar a un nodo específico.
- IntoView: Ajusta la vista del diagrama si se ha aplicado zoom.
- Layout: Cambia entre vista orgánica y jerárquica del diagrama.
Interpretación del esquema
Visualización y conexiones
El mapa muestra la estructura completa de la aplicación mediante nodos y líneas.
- Nodos: Representan componentes principales, como servicios o servidores, y están rodeados por círculos.
- Líneas de conexión: Indican rutas seguidas por las solicitudes, mostrando el número total de llamadas y el tiempo de respuesta promedio. También pueden incluir interacciones bidireccionales.
Interacción con nodos
Al seleccionar un nodo, se muestra una tabla en el lateral izquierdo con los últimos cuatro registros de comunicación, ordenados por fecha. Cada registro es desplegable para ver detalles adicionales.
Identificación de errores
Los errores en las llamadas se resaltan en rojo, mostrando el porcentaje de fallos. Esto facilita priorizar investigaciones y reduce el tiempo de resolución al enfocar la atención en las áreas problemáticas.
Caso de uso
Descripción: Un equipo de operaciones técnicas es responsable de monitorizar una aplicación web alojada en Microsoft Azure. La aplicación está integrada con múltiples servicios, APIs y bases de datos, y los usuarios finales han reportado intermitencias en su rendimiento. El equipo necesita identificar rápidamente los puntos críticos en la infraestructura para resolver el problema.
Análisis del esquema:
- Visualización inicial del esquema:
- El equipo abre el reporte y accede al mapa general de la aplicación.
- Observa los nodos representados como componentes principales de la aplicación (servidores, servicios o bases de datos) y las líneas de conexión que muestran las interacciones entre ellos.
- Las líneas indican el número total de llamadas realizadas entre los componentes y el tiempo promedio de respuesta.
- Identificación de errores:
- Notan que uno de los nodos aparece resaltado en rojo. Esto indica que las solicitudes hacia ese componente tienen un porcentaje significativo de fallos.
- Observan las líneas de conexión para identificar qué otros componentes están afectados por este nodo problemático.
- Investigación de un nodo específico:
- Hacen clic en el nodo resaltado para abrir la tabla de registros en el lateral izquierdo.
- Revisan los últimos cuatro registros de comunicación, ordenados por fecha, para buscar patrones o errores recurrentes.
- Despliegan uno de los registros para analizar los detalles del fallo, incluyendo el tipo de error y su posible origen.
- Ajuste de la visualización:
- Si la topología es extensa, utilizan el botón IntoView para centrar el diagrama.
- Cambian entre las vistas orgánica y jerárquica utilizando el botón Layout para entender mejor las relaciones entre los componentes.
- Toma de decisiones:
- Con base en la información obtenida, identifican que el nodo problemático está relacionado con un servicio de base de datos que tiene un tiempo de respuesta alto.
- Escalan el problema al equipo encargado del mantenimiento de la base de datos con los registros específicos para que puedan resolverlo rápidamente.
Datos adicionales de salud de los servicios
Si deseas acceder a más reportes que los mostrados en la tabla principal, puedes usar el botón Mostrar más, que despliega todos los registros del rango de fechas seleccionado para análisis detallado.
Esta sección del reporte ofrece una visión general del rendimiento y la estabilidad de la aplicación para el tenant analizado.
Todos los gráficos incluyen una leyenda interactiva que mejora la exploración de los datos. Al hacer clic en un elemento de la leyenda, puedes ocultar sus valores en el gráfico, lo que facilita el enfoque en las categorías restantes y mejora la interpretación.
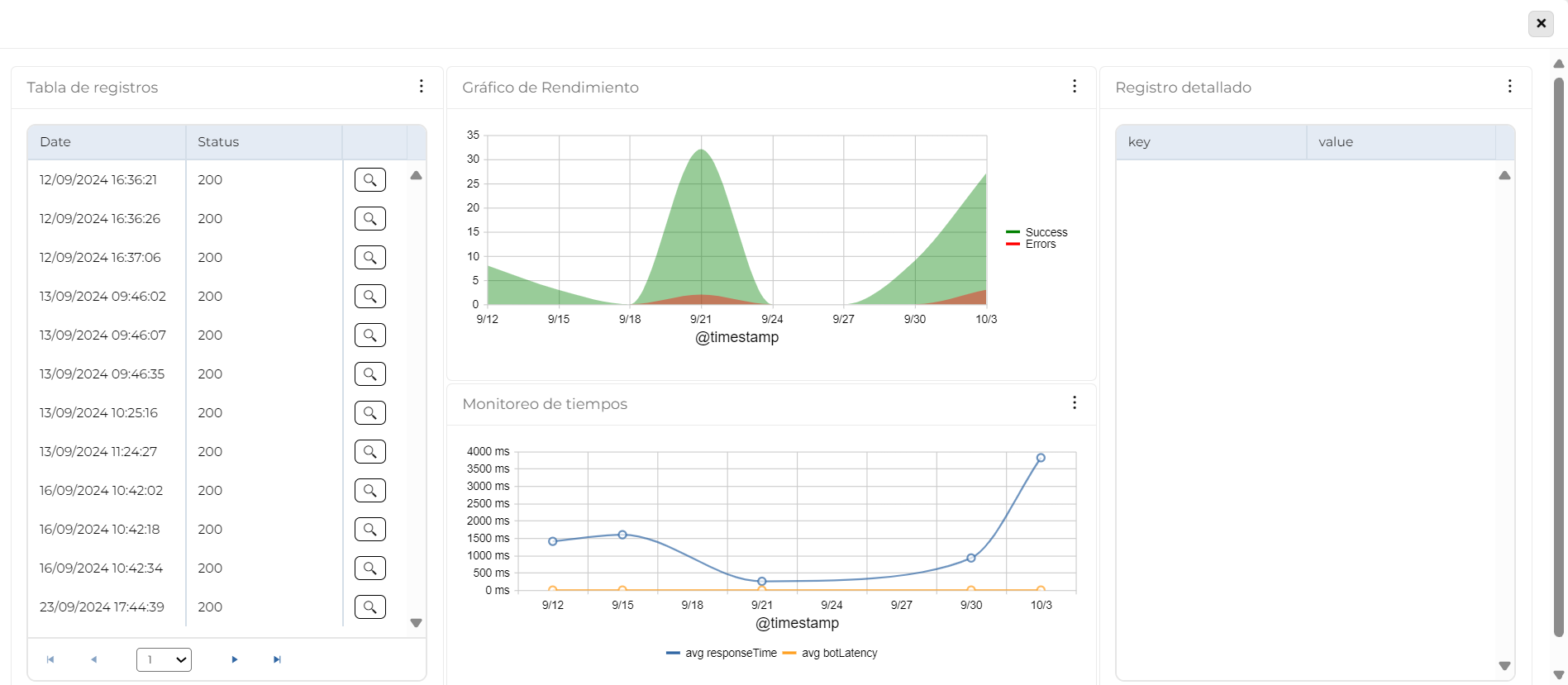
Tabla de registros
Proporciona una visión general del comportamiento de la aplicación mediante el monitoreo de eventos registrados a lo largo del tiempo.
- Datos clave: Fecha y códigos de estado (1xx, 2xx, 3xx, 4xx, 5xx).
- Propósito: Detectar patrones, anomalías y errores recurrentes para diagnosticar problemas y mejorar el rendimiento.
- Acceso rápido: Incluye un botón que lleva a la tabla de Registro Detallado para análisis específico.
Interpretación delos datos
La tabla consta de tres columnas:
- Fecha: Indica cuándo ocurrió el evento.
- Estado: Muestra los códigos devueltos por el servidor en respuesta a las solicitudes:
- 1xx (Informativo): Solicitud recibida; el proceso continúa. Poco común en logs.
- 2xx (Éxito): Solicitud procesada correctamente.
- 3xx (Redirección): Se requiere acción adicional para completar la solicitud.
- 4xx (Error del Cliente): Problemas en la solicitud enviada por el cliente.
- 5xx (Error del Servidor): Problemas en el procesamiento de la solicitud en el servidor.
- Botón para ver detalles adicionales en el Registro Detallado.
Caso de uso
Descripción: Un equipo de soporte técnico está monitoreando el rendimiento de una aplicación crítica para detectar problemas que podrían afectar la experiencia de los usuarios. Un cliente informa que ha experimentado varios errores al intentar completar una operación específica en el sistema. El equipo de soporte accede a esta tabla para investigar el problema.
Uso de la tabla
- Identificar patrones de errores: Al filtrar los registros por la fecha y hora reportadas por el cliente, el equipo nota un aumento en los códigos 4xx (errores del cliente) y 5xx (errores del servidor) durante el período señalado.
- Analizar causas específicas: Los códigos de estado en la columna "Estado" revelan que la mayoría de los errores son 403 (Prohibido) y 500 (Error Interno del Servidor). Esto sugiere problemas relacionados con permisos de usuario y posibles fallos en el backend.
- Acceso rápido al detalle: Utilizando el botón en la tabla, el equipo accede al Registro Detallado para obtener más información sobre los errores, como la URL afectada, parámetros de la solicitud, y mensajes de error específicos.
- Tomar acciones correctivas: Basándose en los datos recopilados, el equipo soluciona un problema de configuración en las políticas de acceso y reinicia un servicio en el servidor afectado, restaurando la funcionalidad del sistema.
Gráfico de rendimiento
Este gráfico proporciona una representación visual del rendimiento de la aplicación a lo largo del tiempo, permitiendo identificar patrones, picos de errores y correlaciones entre registros satisfactorios y errores. Muestra la evolución de ambos tipos de registros en intervalos específicos, lo que facilita evaluar la estabilidad del sistema, detectar anomalías y analizar la confiabilidad del servicio.
Interpretación delos datos
El gráfico de líneas muestra dos tipos de registros:
- Línea de Errores: Representa la cantidad de registros con errores. Permite identificar picos o patrones que podrían indicar problemas.
- Línea de Registros Satisfactorios: Indica la cantidad de registros exitosos. Ayuda a evaluar el rendimiento esperado y su relación con los errores.
Ejes:
- Eje X (Tiempo): Muestra cómo varían los registros a lo largo de diferentes intervalos.
- Eje Y (Cantidad): Representa el número de eventos registrados (satisfactorios y con error) en cada intervalo.
Análisis y utilidad
- Identificar aumentos en los errores y su posible impacto en los registros satisfactorios.
- Visualizar tendencias para diagnosticar problemas y monitorear la confiabilidad del servicio.
- Evaluar si los errores están disminuyendo, permanecen constantes o aumentan, lo que ayuda en la toma de decisiones para mejorar el desempeño de la aplicación.
Caso de uso
Descripción: El equipo de desarrollo y soporte está monitoreando el rendimiento de una aplicación crítica tras implementar una actualización en el sistema. Los usuarios han reportado intermitencias al utilizar ciertas funcionalidades, por lo que es necesario analizar si hay un aumento en los errores y cómo afecta a las operaciones exitosas.
Uso del gráfico para resolver el caso
- Identificar el período afectado: El equipo selecciona el rango de fechas correspondiente a la actualización y los reportes de los usuarios. En el eje X, se observan picos en la línea de errores después de la implementación.
- Correlacionar errores y registros satisfactorios: La disminución en la línea de registros satisfactorios coincide con los picos de errores, indicando un impacto en la experiencia del usuario.
- Analizar los errores: El equipo revisa los registros detallados y encuentra que los errores 500 (Error Interno del Servidor) están relacionados con fallos en el backend provocados por la actualización.
- Tomar acciones correctivas: Se corrige la configuración del servicio afectado y se reinicia el sistema.
- Verificar la recuperación: El gráfico muestra una disminución de los errores y una recuperación de los registros satisfactorios, confirmando que el sistema está operativo nuevamente.
Monitoreo de tiempos
Este gráfico ofrece una visión detallada del rendimiento de la aplicación y del bot a lo largo del tiempo, evaluando su capacidad para responder eficientemente a las solicitudes de los usuarios. Al combinar el tiempo promedio de respuesta de la aplicación y la latencia del bot en un solo gráfico, permite identificar patrones, cuellos de botella y problemas de rendimiento. Esto ayuda a diagnosticar causas específicas de lentitud, diferenciar problemas entre la aplicación y el bot, y tomar decisiones informadas para mejorar la experiencia del usuario y la estabilidad del sistema.
Interpretación de los datos:
El gráfico de líneas representa:
- Tiempo Promedio de Respuesta de la Aplicación: Mide cuánto tiempo tarda la aplicación en responder a las solicitudes. Un tiempo más bajo indica un buen rendimiento, mientras que un aumento puede señalar problemas o sobrecarga.
- Tiempo Promedio de Latencia del Bot: Indica cuánto tiempo tarda el bot en procesar información y generar una respuesta. La latencia puede depender de factores como la carga del servidor, la complejidad de las consultas o la interacción con otras APIs.
Ejes
- Eje X (Tiempo): Muestra la evolución en intervalos como días u horas, según el período analizado.
- Eje Y (Milisegundos): Representa las métricas de tiempo, lo que facilita evaluar el rendimiento de la aplicación y el bot.
Análisis y utilidad
- Identificar patrones de comportamiento, como picos de tiempo o cuellos de botella.
- Diferenciar entre problemas de la aplicación (si el tiempo de respuesta aumenta) y del bot (si la latencia es alta).
- Mejorar la estabilidad del sistema y optimizar la experiencia del usuario.
Caso de uso
Descripción: El equipo de soporte técnico recibe quejas de los usuarios sobre tiempos de respuesta lentos en la aplicación y en el bot. El equipo debe investigar si los retrasos son causados por la aplicación, el bot o ambos, para tomar las medidas correctivas adecuadas.
Uso del gráfico para resolver el caso:
- Identificar el período afectado: El equipo selecciona un rango de tiempo correspondiente a los reportes de los usuarios. En el eje X, se visualizan picos en el tiempo de respuesta de la aplicación y latencia del bot.
- Evaluar el impacto de la aplicación y el bot: El gráfico muestra que, durante los picos de latencia del bot, el tiempo de respuesta de la aplicación se mantiene estable, lo que sugiere que el problema principal radica en el bot.
- Analizar las causas de la latencia: Al observar el comportamiento de la línea de latencia del bot, el equipo nota que los aumentos coinciden con un alto volumen de solicitudes o interacciones con APIs externas, lo que está afectando la capacidad de respuesta del bot.
- Tomar acciones correctivas: El equipo decide optimizar la configuración del bot, como mejorar la eficiencia de las consultas a las APIs externas y distribuir la carga de solicitudes de manera más equilibrada.
- Monitorear los resultados: Después de implementar los cambios, el equipo sigue observando el gráfico. La latencia del bot disminuye, y los tiempos de respuesta mejoran, confirmando que las medidas correctivas han sido efectivas.
Registro detallado
Esta tabla proporciona información específica y detallada sobre un registro seleccionado, facilitando el análisis profundo de eventos individuales. Al presentar los datos en columnas de clave y valor, permite interpretar rápidamente los detalles relevantes, identificar problemas o patrones, y realizar diagnósticos precisos. Este formato estructurado mejora la claridad y facilita el acceso a la información durante el monitoreo o la depuración de la aplicación.
Interpretación de los datos
La tabla muestra los detalles del registro seleccionado en la Tabla de registros y organiza la información en dos columnas: información detallada y específica de cada registro de manera clara y fácil de interpretar. Tiene dos columnas:
- Clave: Nombre o identificador del campo de datos.
- Valor: Contenido o dato específico asociado a cada clave.
Este diseño permite un análisis rápido y eficiente de la información relevante, destacando campos clave para comprender el evento registrado.
Caso de uso
Descripción: El equipo de soporte técnico recibe un reporte de un usuario que experimenta un error intermitente al realizar una acción específica en la aplicación. El equipo necesita investigar el registro correspondiente para identificar la causa del problema y aplicar una solución adecuada.
Uso de la tabla para resolver el caso:
- Acceder al registro específico: El equipo localiza el registro correspondiente en la Tabla de registros mediante la fecha y hora proporcionadas por el usuario.
- Analizar la información detallada: Usando la tabla de Registro Detallado, el equipo observa las claves y valores correspondientes al evento. Por ejemplo, al revisar la clave Error_Code con el valor 500, el equipo identifica que el problema está relacionado con un error interno del servidor.
- Identificar patrones o problemas adicionales: El equipo analiza otros campos clave como Request_URL y User_ID para identificar si el error se repite con ciertos usuarios o solicitudes específicas. Si el campo Request_URL muestra una URL específica que provoca el error, esto ayuda a aislar el problema.
- Tomar acciones correctivas: Con la información obtenida, el equipo puede proceder a revisar la configuración del servidor o los servicios relacionados, identificando que un recurso de backend no está respondiendo correctamente. El equipo toma medidas para corregir la configuración o realizar reinicios de servicio según sea necesario.
- Verificar la solución: Después de aplicar la corrección, el equipo utiliza la tabla para seguir monitorizando los registros y confirmar que los errores se han resuelto y que los registros ya no muestran el mismo patrón de fallos.