Embedding
This functionality allows managing and optimizing the storage of vectors used in similarity analysis and information retrieval in embedding models. Its purpose is to structure information in an efficient knowledge base, facilitating query evaluation by retrieving relevant data from vector representations.
This table is directly related to the action Embedding OpenAI V3.
Access to the Embedding configuration is available in the left-side menu of Lynn’s main interface.
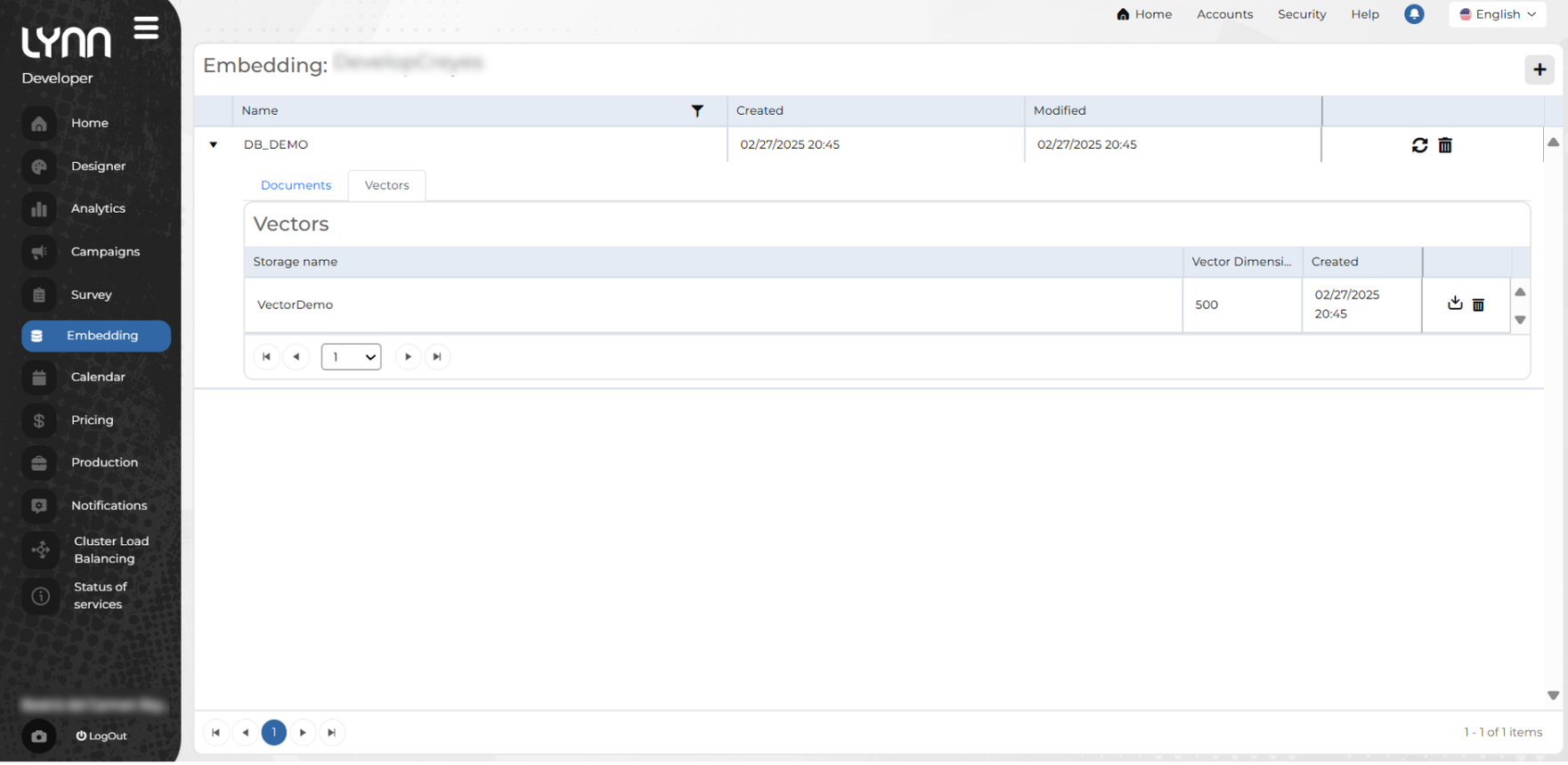
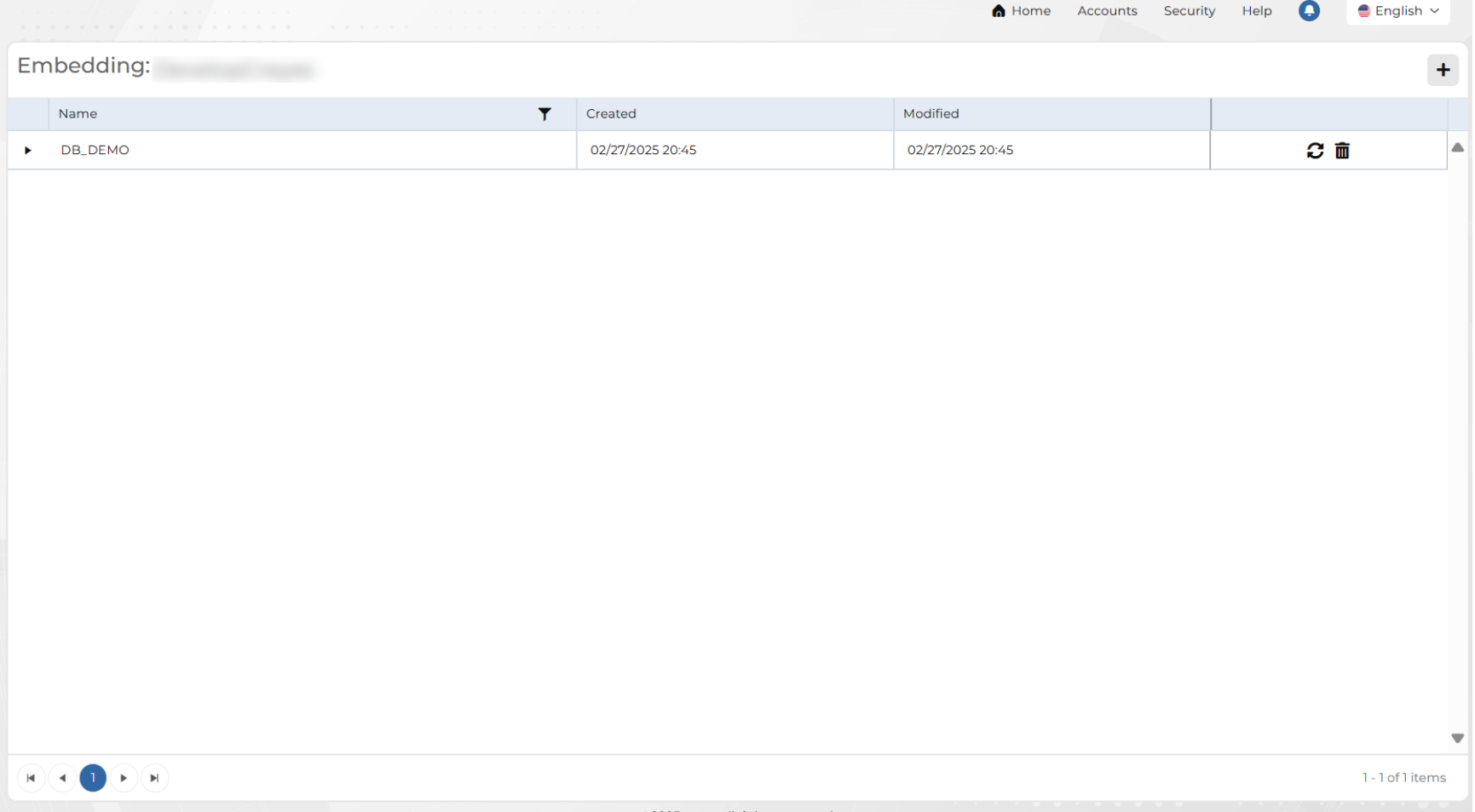
In the main view of the Embedding option, the information is displayed in a table showing the following data:
Name: Embedding name.
Created: Creation date and time.
Modified: Last modification date and time.
Guide to Creating an Embedding
Once in the main view of the Embedding module:
Click the Add button, located in the upper-right corner of the view.
This updates the view to display a set of fields required for the creation and customization of the Embedding.
Complete the required fields:
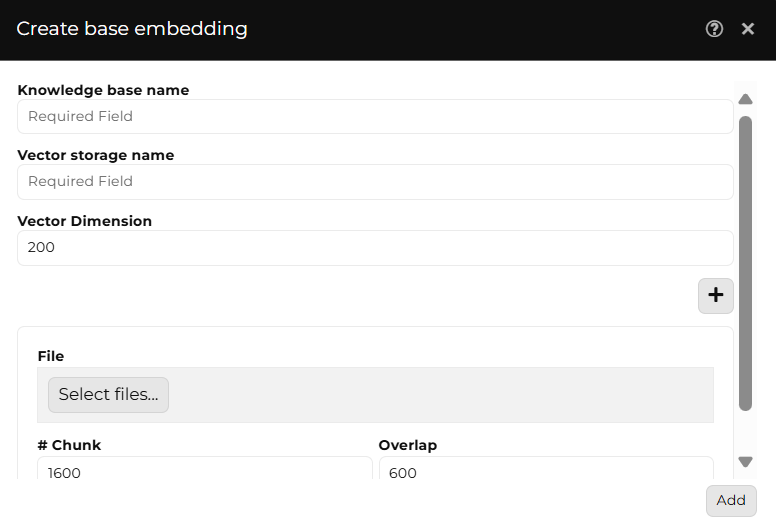
Knowledge base name: A String input field for the unique and descriptive identifier of the Embedding.
Vector storage name: A String input field to define the name of the space where vectors generated from the embedding model are stored, allowing further comparison and analysis.
Vector dimension: A Number input field to define the number of numerical values that make up each vector in the data representation. It affects the accuracy and performance of similarity search.
File: A File input field to upload the document containing the base information that will be processed to generate the embedding vectors.
Note
Currently, only files with the .md (Markdown) extension are supported.
Fragment: A Number input field to define the size of each text section extracted from the original file to be converted into a vector.
Overlap: A Number input field to define the amount of shared text between consecutive fragments, helping to maintain coherence in analysis and improve information retrieval in vector searches.
Note
The form includes an Add (+) button that allows uploading multiple files with base information or knowledge bases. Each file can be configured with the Fragment and Overlap fields.
Click the Add button after completing all configuration fields.
Embedding Table
Embedding creation data is presented in a table organized into different sections for easy consultation and management. When expanding an embedding, the following tabs are displayed:
- Name: Embedding name.
- Created: Creation date and time.
- Modified: Last modification date and time.
- Documents: Contains the list of files used to generate the embedding, along with segmentation parameters.
- Vectors: Displays the configuration of the storage for the vectors generated from the processed documents.
- Reprocess: Process uploaded documents.
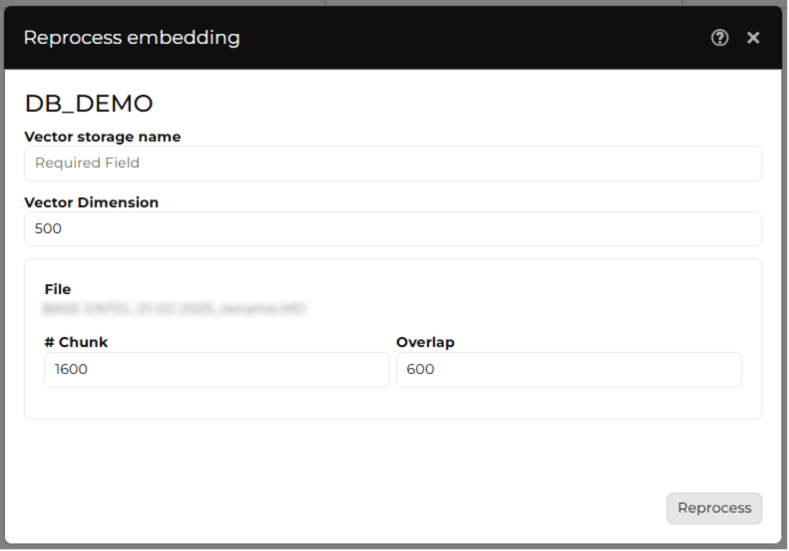
Reprocess
This functionality allows reprocessing documents stored in the knowledge base, whether they are previously processed documents or files recently uploaded through the Add Document option in the Documents tab of the embedding table.
Steps to reprocess a document:
- Click on the Reprocess option.
- Verify that the documents intended to be used as the knowledge base are in the list. If a document is missing, it must first be Added.
- If the document has not been processed before, enter the following values:
- Fragment size: Number of characters in each text block.
- Overlap: Amount of text shared between consecutive fragments.
- Click the Reprocess button to start processing with the defined parameters.
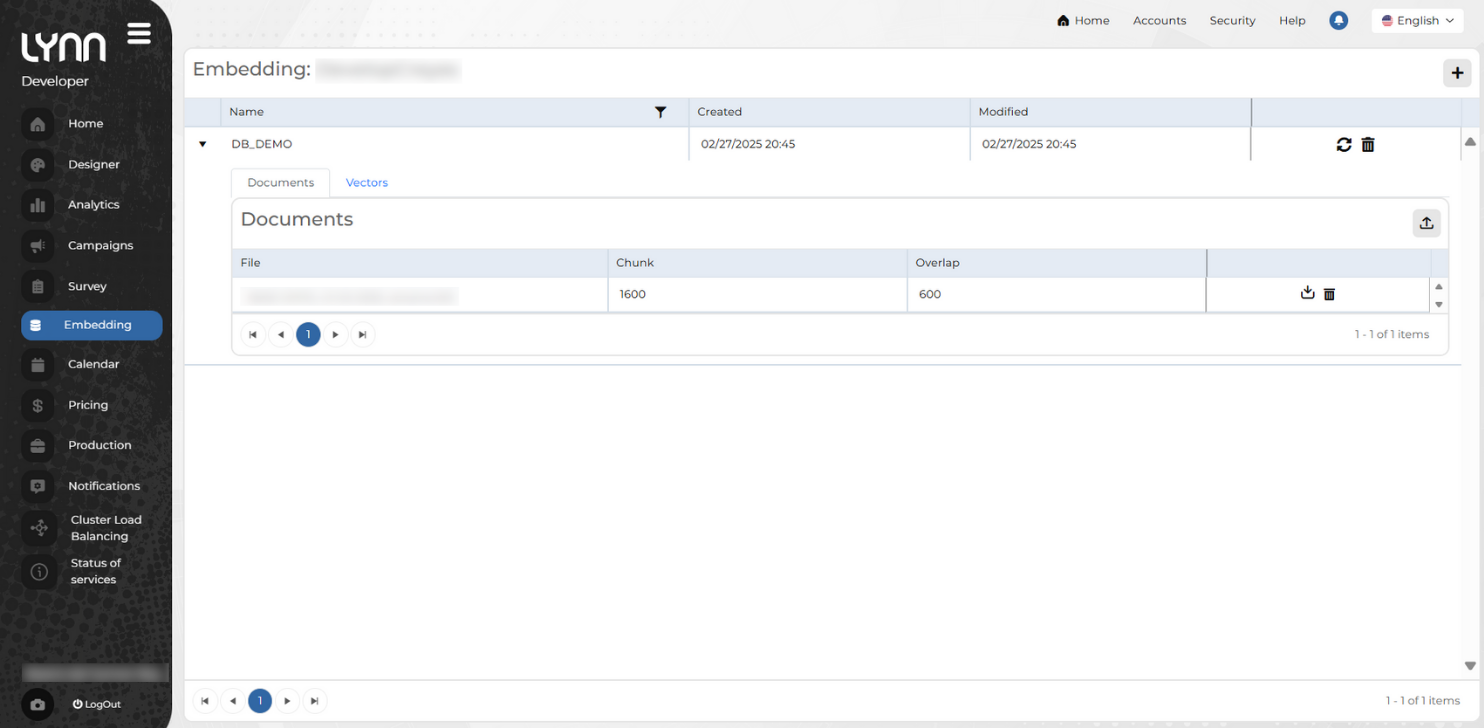
Tab: Documents
This section shows the files used for embedding creation, along with their segmentation parameters, displaying data such as:
- File: Name of the processed document.
- Fragment: Size in characters of each text block converted into a vector.
- Overlap: Amount of shared text between consecutive fragments to improve semantic continuity.
- Download documents
- Delete documents
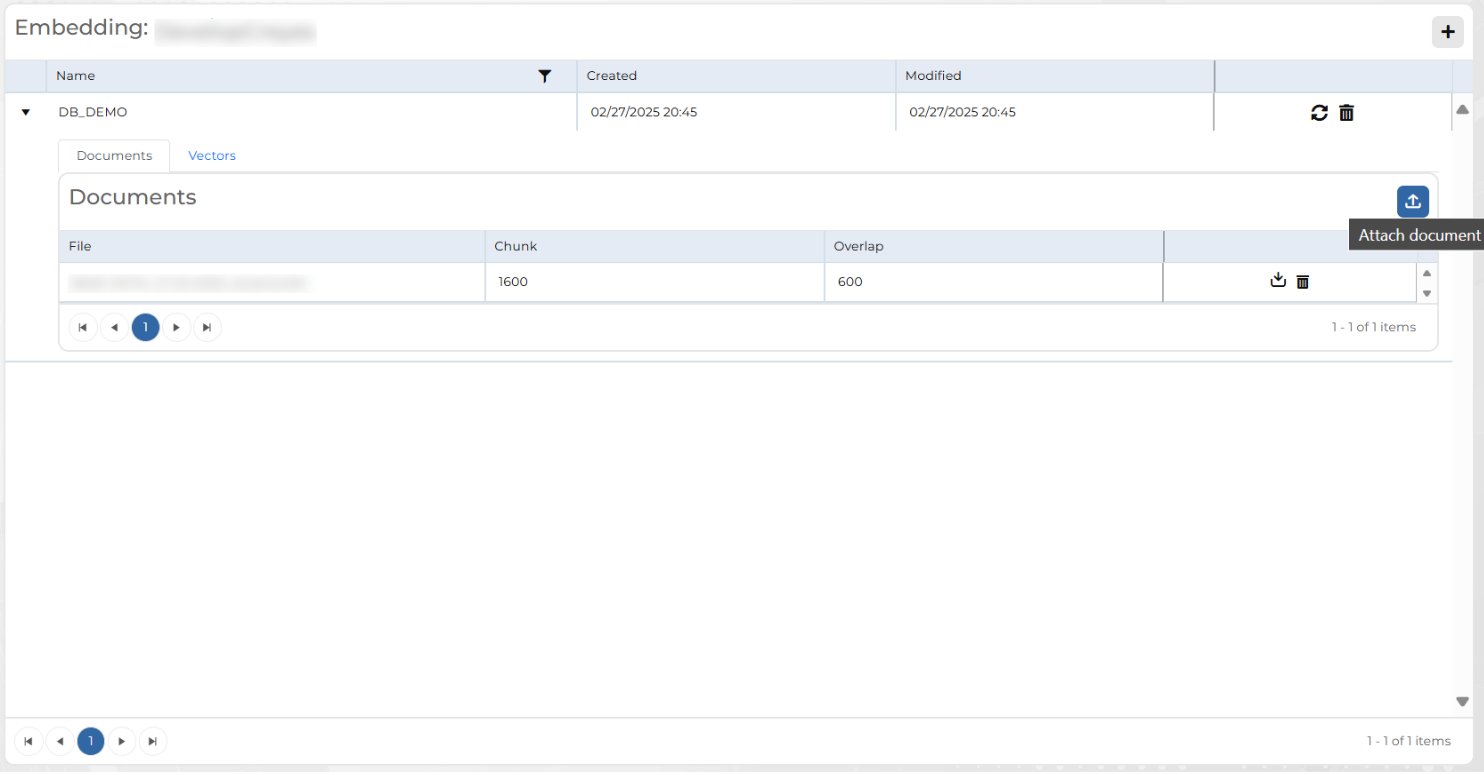
Add Document
Allows uploading a file to the knowledge base without processing it immediately. The document is stored in the system, but no vector representations are generated, nor is segmentation applied at this stage. Processing and vector generation can be performed later.
Important
When a document is added, fragments and overlap are not defined because processing has not yet occurred. The document remains available for processing later through the Reprocess option.
Tab: Vectors
Displays the configuration of the storage for the vectors generated from the processed documents.
- Storage name: Identifier of the space where the generated vectors are stored.
- Vector dimension: Number of numerical values that make up each vector, impacting the accuracy of vector searches.
- Created: Date and time of vector storage creation.
- Download vectors
- Delete vectors