



Genesys Cloud Audio Connector
This channel enables communication between Lynn and the Genesys Cloud voice service, using Speech-to-Text (STT) and Text-to-Speech (TTS) mechanisms to provide a complete conversational experience. While Genesys handles the audio, Lynn interprets and responds using processed text. Therefore, the IVR design can be fully managed from Lynn.
Prerequisites
- Credentials and setup for Text-to-Speech - ElevenLabs.
Active ElevenLabs account.
Valid API Key. How to obtain it:
- Sign in at ElevenLabs
- Click on My Account in the bottom left corner.
- Select API Keys.
- Click Create API Key to generate a new key.
Important
The full key will only be displayed once upon creation. Make sure to copy and store it safely. Afterward, only the last four characters will be visible.
Voice configured in your account (retrieve the Voice ID from the ElevenLabs dashboard).
Supported output format (mp3, wav).
(Optional) Language, style, or voice parameters configured according to the flow.
- Credentials and setup for Speech-to-Text (Azure Speech Services)
- Active Microsoft Azure account.
- Speech service created in the Azure portal.
- Required keys:
- Speech API Key
- How to obtain it:
- Go to the Azure portal
- Create or access your Speech Service resource.
- Navigate to Keys and Endpoint.
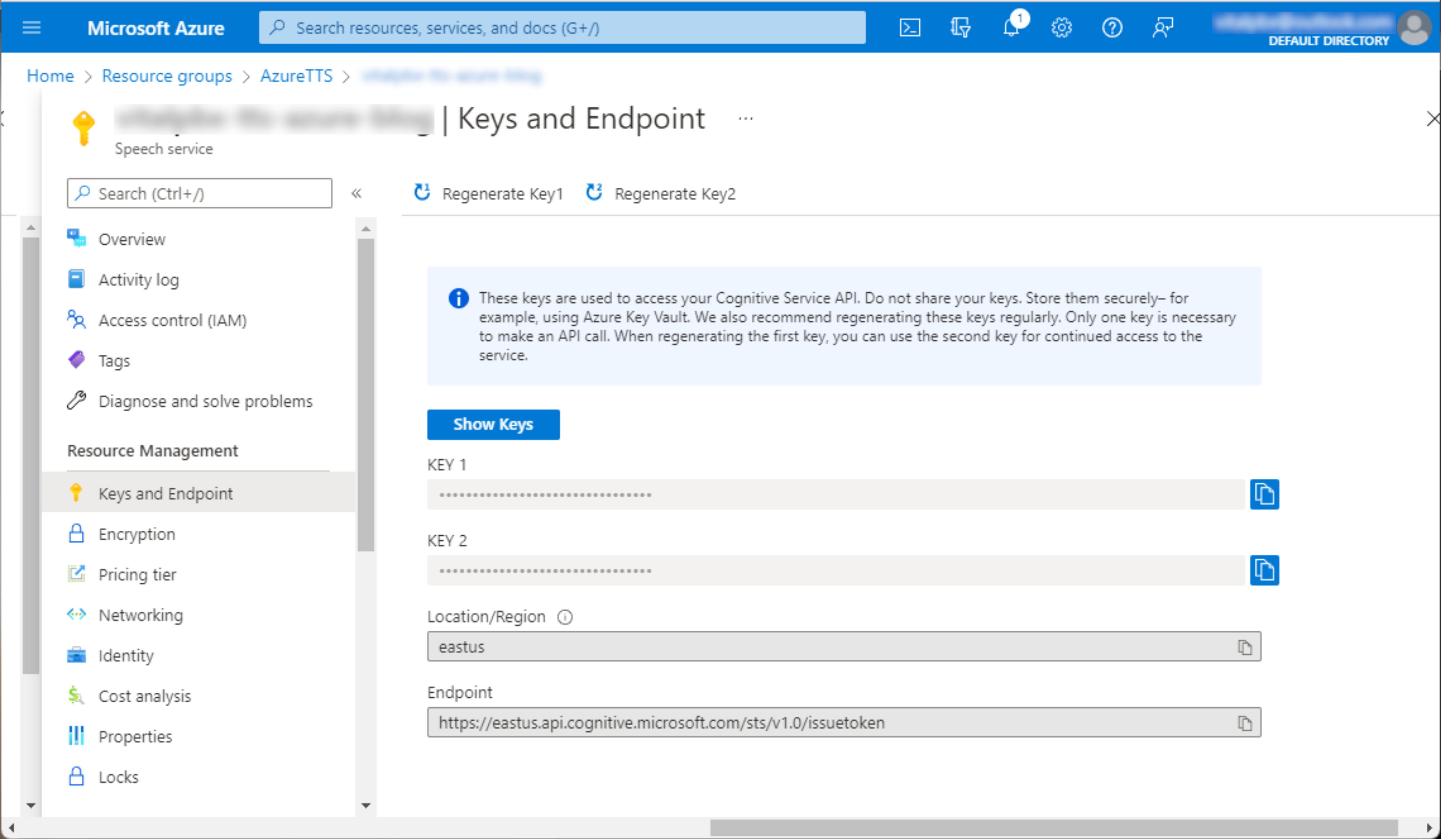
- How to obtain it:
- Region corresponding to the resource (e.g., eastus).
- Speech API Key
- Language configured for voice recognition (e.g., es-ES, en-US).
- Permissions enabled to consume the Speech-to-Text endpoint.
- Verify that the submitted audio format is compatible (e.g., PCM 16 kHz, mono).
Channel Creation Steps
- Log in to Lynn.
- Select Designer from the main menu on the left.
- Right-click on the designer's free area.
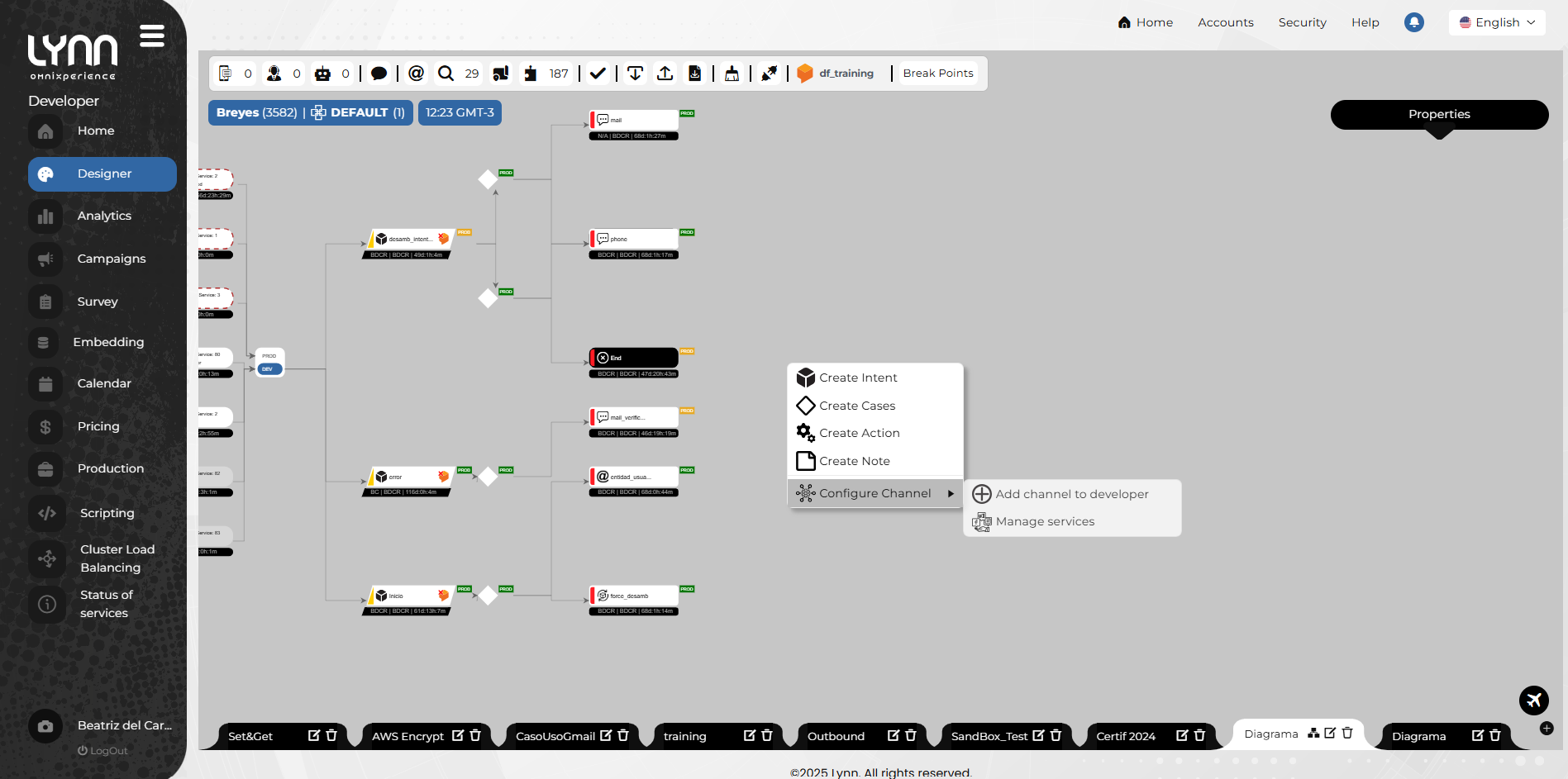
A context menu will appear.
- Select Configure channel, then Add channel to [Environment].
- Choose Genesys Cloud Audio Connector from the list of available channels in Lynn.
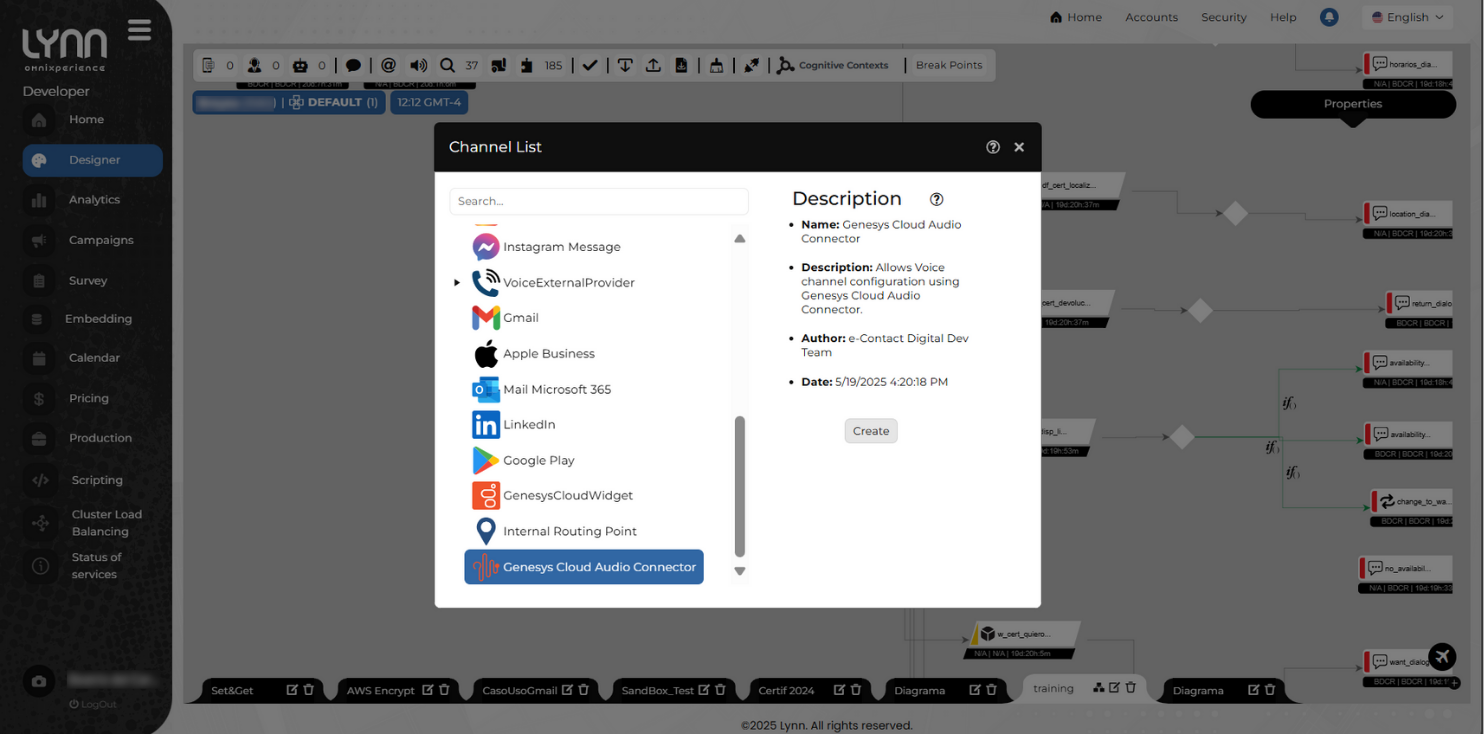
- Click Create.
A window will appear with the required configuration fields.
- Click the Verify button to initialize parameter validation, then click Create.
A popup will confirm the successful creation of the channel.
- Activate the channel: right-click the channel bubble. From the context menu, select Activate. The bubble will turn solid white, indicating the channel is active.
Channel Configuration Fields
For the channel to function correctly, specific configurations must be defined, including the engines used to process audio: one to convert voice to text (Speech-to-Text) and another to synthesize audio from text (Text-to-Speech).
Text-to-Speech Provider Configuration
Select a provider (TTS_PROVIDER): A select field to choose the provider that converts text into audio using synthetic voices.
Note
Currently, the only available TTS provider for this channel is ElevenLabs.
Enter credentials (TTS_CREDENTIALS): A text field to input the ElevenLabs API Key. Refer to the Prerequisites section for configuration details.
Important
This field includes a validation button to immediately verify if the entered credentials are correct before saving the configuration. Upon clicking Validate, the system will attempt to connect to the service:
- If authentication is successful, a green check icon will appear.
- If credentials are incorrect or a connection error occurs, a red warning icon will display, allowing you to correct the input.
Select one of the voices available in your account (TTS_VOICE): A select field to choose from the voices enabled in ElevenLabs.
Voice configuration (TTS_VOICE_SETTINGS): A section that groups fields to customize the generated speech output, adjusting tone, naturalness, style, and speed. All numeric fields must be filled with values between 0 and 1.
Stability: A number field that controls the emotional consistency of the voice.
- Low values: more emotional variation.
- High values: more stable and monotone voice.
Note
Default value:
0.5.Similarity Boost: A number field to increase similarity to the original voice.
- High values improve likeness but may introduce artifacts if the source has noise.
Note
Default value:
0.75.Style: A number field to amplify the speaker's style.
- High values may exaggerate expressiveness, affecting stability and increasing latency.
Note
Default value:
0.0.Use Speaker Boost: A select field to enable or disable reinforcement of the speaker's vocal identity.
- Set to
trueto reinforce identity, especially useful when using multiple voices.
Note
Default value:
false. Enabling may increase latency and resource usage.- Set to
Speed: A select field to define the speech playback speed.
- Values below 1.0 slow down speech; values above 1.0 speed it up.
- Example: 1.0 is normal speed, 1.2 is 20% faster.
Note
Default value:
1.0. Recommended minimum:0.7(30% slower); max:1.2(20% faster)Model: A select field to specify the voice synthesis model.
Speech-to-Text Provider Configuration
Select a provider (STT_PROVIDER): A select field to choose the STT engine.
Important
Currently, the only available Speech-to-Text provider for this channel is Azure.
Enter credentials (STT_CREDENTIALS):
A section that groups fields to authenticate with Azure Speech Services. These values must be obtained from the Azure portal.
Endpoint: A text field to input the base URL for Azure Speech. This identifies the service connection. See Region endpoints
SubscriptionKey: A text field for the Azure Speech subscription key. This key authenticates requests to the service and is tied to an Azure account with Speech-to-Text permissions. See Prerequisites for more.
Region: A text field with the geographic region where the service is deployed (e.g.,
eastus).Note
The region value is part of the endpoint and may be used to auto-complete this field.
Language: A select field to choose the language code for the expected audio. For example:
es-ES(Spanish - Spain),en-US(English - US). This improves recognition accuracy.
Functional Parameters
Idle timeout to end interaction from Lynn (milliseconds): A number field to define the max user inactivity time (no voice input) before Lynn auto-closes the session. Expressed in milliseconds.
Wait time before starting voice recognition (seconds): A select field to set an initial delay (in seconds) before voice recognition starts. Useful to avoid capturing irrelevant sounds or overlapping system messages.
Randomly executed phrases while the assistant session is being created: A textarea field to enter a list of phrases that may be randomly spoken while initializing the assistant, to keep the user informed or entertained.
Intent to execute when silence is detected: A select field to define which intent runs when prolonged user silence is detected, helping resume or redirect the conversation.
Intent to execute when the client interrupts the message: A select field to define which intent is triggered if the user starts speaking while Lynn is playing a message, allowing contextual handling of interruptions.
Intent to execute when an error occurs: A select field to define which intent runs if a voice processing error occurs (e.g., STT failure or connection issues).
Audio buffer size to send to the STT provider (in seconds): A select field to set the audio chunk duration (in seconds) sent to the STT provider. This affects both recognition accuracy and response time.
Allow voice interruptions: A radio button field to enable or disable the user's ability to interrupt spoken messages with their voice. If enabled, Lynn stops speaking and processes the input.
Silence threshold (in seconds): A select field to define how many seconds of silence are interpreted as the end of a sentence. Lower values increase sensitivity to brief pauses.